Preparation material

Design guru : Patternwise prep (pattern study, top 75 questions)
Additional open Course
Dynamic Programming youtube
Read all data structure at high level link
Topic to be covered
1. 75 leetcode questions
2. 150 leetcode questions
3. Neetcode questions
Questions Asked:
Write a program to find denomination exchange when payment made and change has to be given. if currency denomination is like 100, 50, 20, 10, 5 , 1 .
You are given an array prices where prices[i] is the price of a given stock on the ith day.You want to maximize your profit by choosing a single day to buy one stock and choosing a different day in the future to sell that stock. Return the maximum profit you can achieve from this transaction. If you cannot achieve any profit, return 0.write a program in java for above statement
You are given an array prices where prices[i] is the price of a given stock on the ith day.You want to maximize your profit by choosing a single day to buy one stock and choosing a different day in the future to sell that stock. Return the maximum profit you can achieve from this transaction. If you cannot achieve any profit, return 0.write a program in java for above statement
Given a string s, find the length of the longest without duplicate characters.
find nextprim number from given prime number
find if string is palindrome provided if you can remove atmost 1 character from string
Time and Space Complexity Cheatsheet


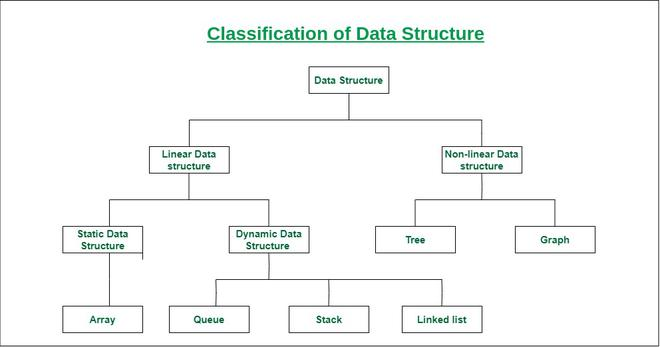
Type of Data Structure
Question Collection
- Pattern Question collection Grokking-the-Coding-Interview-Patterns
- Patternwise solution Several-Coding-Patterns
- longest common subsequence
- longest common substring
- longst common suffix
- lonngest common prefix
- Longest Common Prefix using Sorting
- Longest Common Prefix using Word by Word Matching
- Deadlock of 2 threads
- 3 thread printing in sequence
- Minimum cost path in graph
String Question
- How do you reverse a given string in place? (solution)
- How do you print duplicate characters from a string? (solution)
- How do you check if two strings are anagrams of each other? (solution)
- How do you find all the permutations of a string? (solution)
- How can a given string be reversed using recursion? (solution)
- How do you check if a string contains only digits? (solution)
- How do you find duplicate characters in a given string? (solution)
- How do you count a number of vowels and consonants in a given string? (solution)
- How do you count the occurrence of a given character in a string? (solution)
- How do you print the first non-repeated character from a string? (solution)
- How do you convert a given String into int like the atoi()? (solution)
- How do you reverse words in a given sentence without using any library method? (solution)
- How do you check if two strings are a rotation of each other? (solution)
- How do you check if a given string is a palindrome? (solution)
- How do you find the length of the longest substring without repeating characters? (solution)
- Given string str, How do you find the longest palindromic substring in str? (solution)
- How to convert a byte array to String? (solution)
- how to remove the duplicate character from String? (solution)
- How to find the maximum occurring character in given String? (solution)
- How do you remove a given character from String? (solution)
- Given an array of strings, find the most frequent word in a given array, I mean, the string that appears the most in the array. In the case of a tie, the string that is the smallest (lexicographically) is printed. (solution)
Question Collection
By mastering these 22 DSA patterns
1. Fast and Slow Pointer
- Cycle detection method
- O(1) space efficiency
- Linked list problems
2. Merge Intervals
- Sort and merge
- O(n log n) complexity
- Overlapping interval handling
3. Sliding Window
- Fixed/variable window
- O(n) time optimization
- Subarray/substring problems
4. Islands (Matrix Traversal)
- DFS/BFS traversal
- Connected component detection
- 2D grid problems
5. Two Pointers
- Dual pointer strategy
- Linear time complexity
- Array/list problems
6. Cyclic Sort
- Sorting in cycles
- O(n) time complexity
- Constant space usage
7. In-place Reversal of Linked List
- Reverse without extra space
- O(n) time efficiency
- Pointer manipulation technique
8. Breadth First Search
- Level-by-level traversal
- Uses queue structure
- Shortest path problems
9. Depth First Search
- Recursive/backtracking approach
- Uses stack (or recursion)
- Tree/graph traversal
10. Two Heaps
- Max and min heaps
- Median tracking efficiently
- O(log n) insertions
11. Subsets
- Generate all subsets
- Recursive or iterative
- Backtracking or bitmasking
12. Modified Binary Search
- Search in variations
- O(log n) time
- Rotated/specialized arrays
13. Bitwise XOR
- Toggle bits operation
- O(1) space complexity
- Efficient for pairing
14. Top 'K' elements
- Use heap/quickselect
- O(n log k) time
- Efficient selection problem
15. K-way Merge
- Merge sorted lists
- Min-heap based approach
- O(n log k) complexity
16. 0/1 Knapsack (Dynamic Programming)
- Choose or skip items
- O(n * W) complexity
- Maximize value selection
17. Unbounded Knapsack (Dynamic Programming)
- Unlimited item choices
- O(n * W) complexity
- Multiple item selection
18. Topological Sort (Graphs)
- Directed acyclic graph
- Order dependency resolution
- Uses DFS or BFS
19. Monotonic Stack
- Maintain increasing/decreasing stack
- Optimized for range queries
- O(n) time complexity
20. Backtracking
- Recursive decision-making
- Explore all possibilities
- Pruning with constraints
21. Union Find
- Track and merge connected components
- Used for disjoint sets
- Great for network connectivity
22. Greedy Algorithm
- Make locally optimal choices
- Efficient for problems with optimal substructure
- Covers tasks like activity selection, minimum coins